犬猫判別AIを作って愛犬を判別してみる(実践編)
2023-03-12
初めに
前回、GPUを使って機械学習をしたよという記事を書きました。でも正直あのレベルならGPUがなくてもできる。じゃあ、GPUを使って何がしたい?そう、もっと大量のデータ、ユニットを使った画像識別でしょ!ということで犬と猫を見分けるAIを作ります。最後にわが愛犬、チェリーちゃんをモデルに突っ込んでちゃんと犬と判別されるか実験するぜ!
犬猫判別用データを作る
今回は、Kaggleという機械学習の精度を競うプラットフォームで提供された「Dogs vs Cats」というデータを使います。犬と猫の画像が12500枚ずつ、計25000枚のカラー画像が含まれたデータです。でも今回は実践編。そんなたくさんのデータがある方が社会に出たら珍しい。そこで、今回は難易度を上げてこの中の2000枚ずつを使ってモデルを学習させてみようと思います。データが少ないと訓練用データを学習しすぎてモデルの精度が下がる過学習を起こしやすいです。工夫してやってみます。
データをダウンロードして犬と猫それぞれの画像を訓練用1000枚、評価用500枚、テスト用500枚に分けます。
# 中身がtrain1000、validation500、test500になってるか確認
cat("total training cat images:",length(list.files(train_cats_dir)),"\n")
## total training cat images: 1000
cat("total training dog images:",length(list.files(train_dogs_dir)),"\n")
## total training dog images: 1000
cat("total validation cat images:",length(list.files(validation_cats_dir)),"\n")
## total validation cat images: 500
cat("total validation dog images:",length(list.files(validation_dogs_dir)),"\n")
## total validation dog images: 500
cat("total test cat images:",length(list.files(test_cats_dir)),"\n")
## total test cat images: 500
cat("total test dog images:",length(list.files(test_dogs_dir)),"\n")
## total test dog images: 500ちゃんと分けられています。何枚か中身を表示してみます。

かわいいですね。でもかわいくない点が1つあります。画像の大きさや形が全然ちがーう!これだと画像データのままモデルを学習できないので形を合わせる必要があります。さらに、カラーを構成する青赤緑の成分をデコードして…めんどくさいですね。 なんとkerasにはこの過程を自動的に変換してくれるimage_data_generater()関数というスーパー便利な関数があります!さっそくやってみる。
# 色のスケーリング
train_datagen <- image_data_generator(rescale = 1/255)
validation_datagen <- image_data_generator(rescale = 1/255)
# めっちゃ便利な関数で一括処理
train_generator <- flow_images_from_directory(
train_dir,
train_datagen,
target_size = c(150,150),
batch_size = 16,
class_mode = "binary"
)
validation_generator <- flow_images_from_directory(
validation_dir,
validation_datagen,
target_size = c(150,150),
batch_size = 16,
class_mode = "binary"
)
batch <- generator_next(train_generator)
str(batch)## List of 2
## $ : num [1:16, 1:150, 1:150, 1:3] 0.267 0.565 0.933 0.278 0.247 ...
## $ : num [1:16(1d)] 0 0 0 0 1 1 1 1 0 1 ...20枚ずつ、150×150にそろえて0,1のラベル付けをしています。手作業でやったら時間がかかることが関数で用意されているのは便利ですね。これでデータの準備は終わり。
まずはシンプルにモデルを作ってみる
今回はCNNと呼ばれる畳み込みニューラルネットを使います。簡単に言うと2×2や3×3のランダムな行列を画像の部分部分と内積をとることで画像の特徴を捉えることができます。また、画像の一部のうち最も大きな値を代表地として画像を圧縮するマックスプーリング層やランダムに重みをリセットするドロップアウト層も入れた本格的なモデルです。
model <- keras_model_sequential() %>%
layer_conv_2d(filters = 32, kernel_size = c(3,3),activation = "relu",
input_shape = c(150,150,3)) %>%
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_conv_2d(filters = 64, kernel_size = c(3,3),activation = "relu") %>%
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_conv_2d(filters = 128, kernel_size = c(3,3),activation = "relu") %>%
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_conv_2d(filters = 128, kernel_size = c(3,3),activation = "relu") %>%
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_flatten() %>%
layer_dense(units = 512, activation = "relu") %>%
layer_dense(units = 1, activation = "sigmoid")
summary(model) ## Model: "sequential"
## ________________________________________________________________________________
## Layer (type) Output Shape Param #
## ================================================================================
## conv2d_3 (Conv2D) (None, 148, 148, 32) 896
## max_pooling2d_3 (MaxPooling2D) (None, 74, 74, 32) 0
## conv2d_2 (Conv2D) (None, 72, 72, 64) 18496
## max_pooling2d_2 (MaxPooling2D) (None, 36, 36, 64) 0
## conv2d_1 (Conv2D) (None, 34, 34, 128) 73856
## max_pooling2d_1 (MaxPooling2D) (None, 17, 17, 128) 0
## conv2d (Conv2D) (None, 15, 15, 128) 147584
## max_pooling2d (MaxPooling2D) (None, 7, 7, 128) 0
## flatten (Flatten) (None, 6272) 0
## dense_1 (Dense) (None, 512) 3211776
## dense (Dense) (None, 1) 513
## ================================================================================
## Total params: 3,453,121
## Trainable params: 3,453,121
## Non-trainable params: 0
## ________________________________________________________________________________パラメタの数が「3,453,121」まで増えています。mnistの時とはけた違いですな。
モデルが決まったらコンパイルして学習させます。
model %>% compile(
loss = "binary_crossentropy",
optimizer = optimizer_rmsprop(learning_rate = 1e-4),
metrics = c("acc")
)
history <- model %>% fit(
train_generator,
steps_per_epoch = 100,
epochs = 100,
validation_data = validation_generator,
validation_steps = 50
)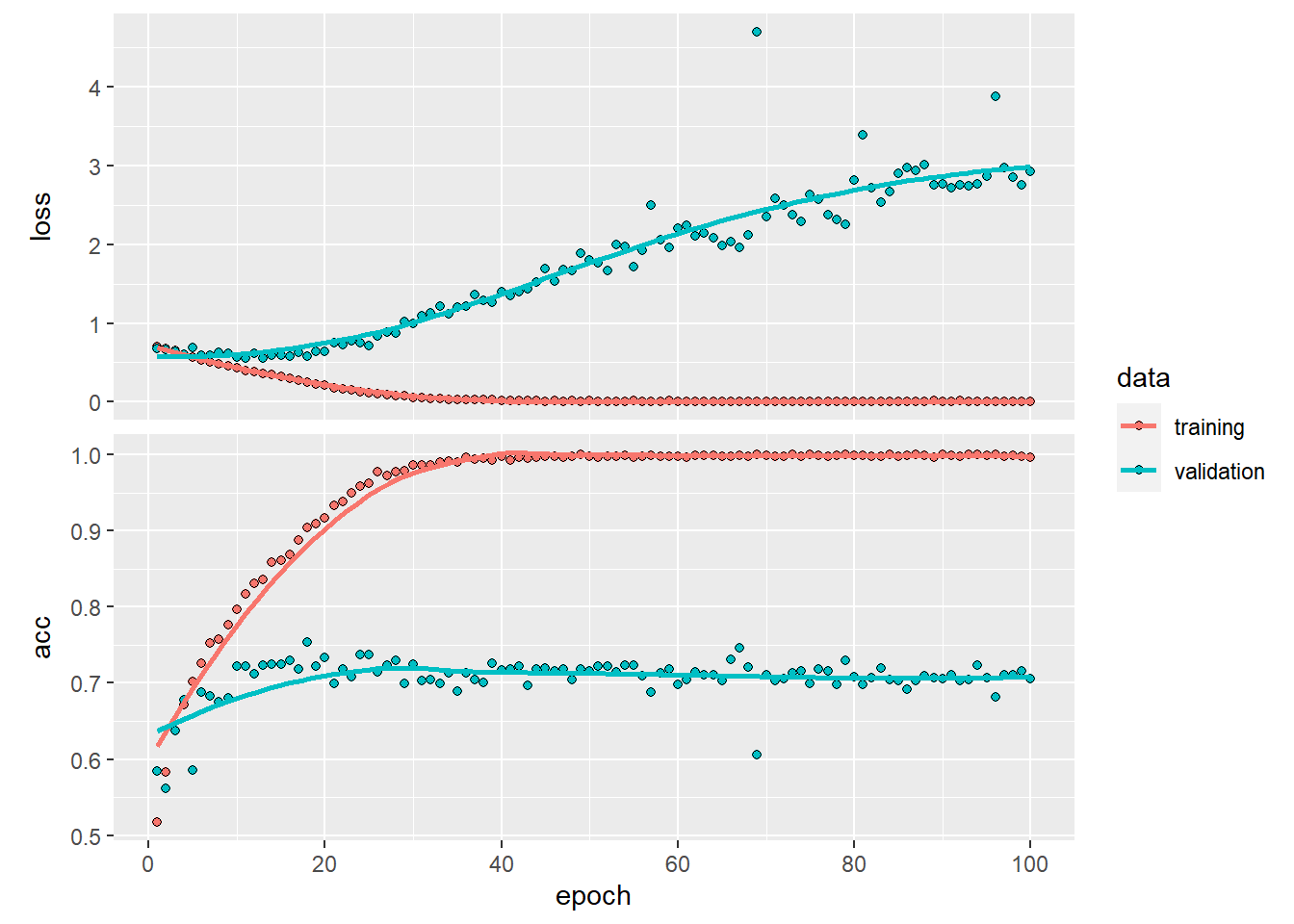
valと表示されているのが学習時にどれぐらい過学習しているかを見るための指標になります。評価データの正確度は70%程度。今回はデータが少ないため過学習するという予想の元、過学習しにくくなるような層を追加してモデルを組みました。val_lossが後半に行くにつれて増えていくのでまだ過学習を起こしてます。
データ拡張をして、訓練済みCNNを利用する
今回、データが少ないために十分な学習を行うのが困難でした(自分で減らしたからだろ)。そこで変換器を使ったデータ拡張をしてみます。
ここでは詳しい説明は端折りますが、既存の訓練データから新たな訓練データを作ることで過学習を抑制します。
datagen <- image_data_generator(
rescale = 1/255,
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = TRUE,
fill_mode = "nearest"
)
# 実際の変換を見てみる
fnames <- list.files(train_cats_dir, full.names = TRUE)
img_path <- fnames[[3]]
img <- image_load(img_path, target_size = c(150,150))
img_array <- image_to_array(img)
img_array <- array_reshape(img_array, c(1, 150, 150, 3))
augmentation_generator <- flow_images_from_data(
img_array,
generator = datagen,
batch_size = 1
)
op <- par(mfrow = c(2, 2), pty = "s", mar = c(1, 0, 1, 0))
for (i in 1:4) {
batch <- generator_next(augmentation_generator)
}
一枚の画像を引き延ばしたり、反転させたり、回転させたり… 一見ずるく見えますがこれだけでも過学習を抑えることができます。
さらにさらに、1からCCNNを入れたモデルを作るのではなく、すでに訓練されたネットワークを使って、より高い制度の犬猫判別AIを作っていきます。
今回はImageNetと呼ばれる、動物や日用生活品を訓練したCNNを用いて再度学習させます。これもずるく聞こえますが、少ない画像データで機械学習をする際によく用いられる方法です。このImageNetを用いて訓練されたモデルはkerasに含まれているのでモデルの中に記述するだけで利用することができます。素晴らしいですね。今回はVGG16モデルを使用します。
conv_base <- application_vgg16(
weights = "imagenet",
include_top = FALSE,
input_shape = c(150, 150, 3)
)
conv_base## Model: "vgg16"
## ________________________________________________________________________________
## Layer (type) Output Shape Param #
## ================================================================================
## input_1 (InputLayer) [(None, 150, 150, 3)] 0
## block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
## block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
## block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
## block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
## block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
## block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
## block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
## block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
## block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
## block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
## block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
## block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
## block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
## block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
## block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
## block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
## block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
## block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
## ================================================================================
## Total params: 14,714,688
## Trainable params: 14,714,688
## Non-trainable params: 0
## ________________________________________________________________________________パラメタ数が馬鹿でかいですね。さっきのモデルにこのVGG16をくっつけていきます。今回は犬猫判別なのでVGG16の中身を壊さないよう気を付けつつ実装します。モデルはこちら
model <- keras_model_sequential() %>%
conv_base() %>%
layer_flatten() %>%
layer_dense(units = 256, activation = "relu") %>%
layer_dense(units = 1, activation = "sigmoid")
model## Model: "sequential_1"
## ________________________________________________________________________________
## Layer (type) Output Shape Param #
## ================================================================================
## vgg16 (Functional) (None, 4, 4, 512) 14714688
## flatten_1 (Flatten) (None, 8192) 0
## dense_3 (Dense) (None, 256) 2097408
## dense_2 (Dense) (None, 1) 257
## ================================================================================
## Total params: 16,812,353
## Trainable params: 16,812,353
## Non-trainable params: 0
## ________________________________________________________________________________VGG16が最初の層になっており、平たんにして接続しています。先ほどのシンプルなモデルよりさらにパラメタ数が一桁増えました。ここまでくるとCPUでは途方もない時間がかかるか、発熱しすぎて止まってしまいます(実体験)。
ここで畳み込みベースを凍結させてうんぬんがありますがとりあえずコンパイルまでスキップします。
# モデルのコンパイル
model %>% compile(
loss = "binary_crossentropy",
optimizer = optimizer_rmsprop(learning_rate = 2e-5),
metrics = c("acc")
)コンパイルが済んだので学習させましょう。
# 学習
history <- model %>% fit(
train_generator,
steps_per_epoch = 100,
epochs = 30,
validation_data = validation_generator,
validation_steps = 50
)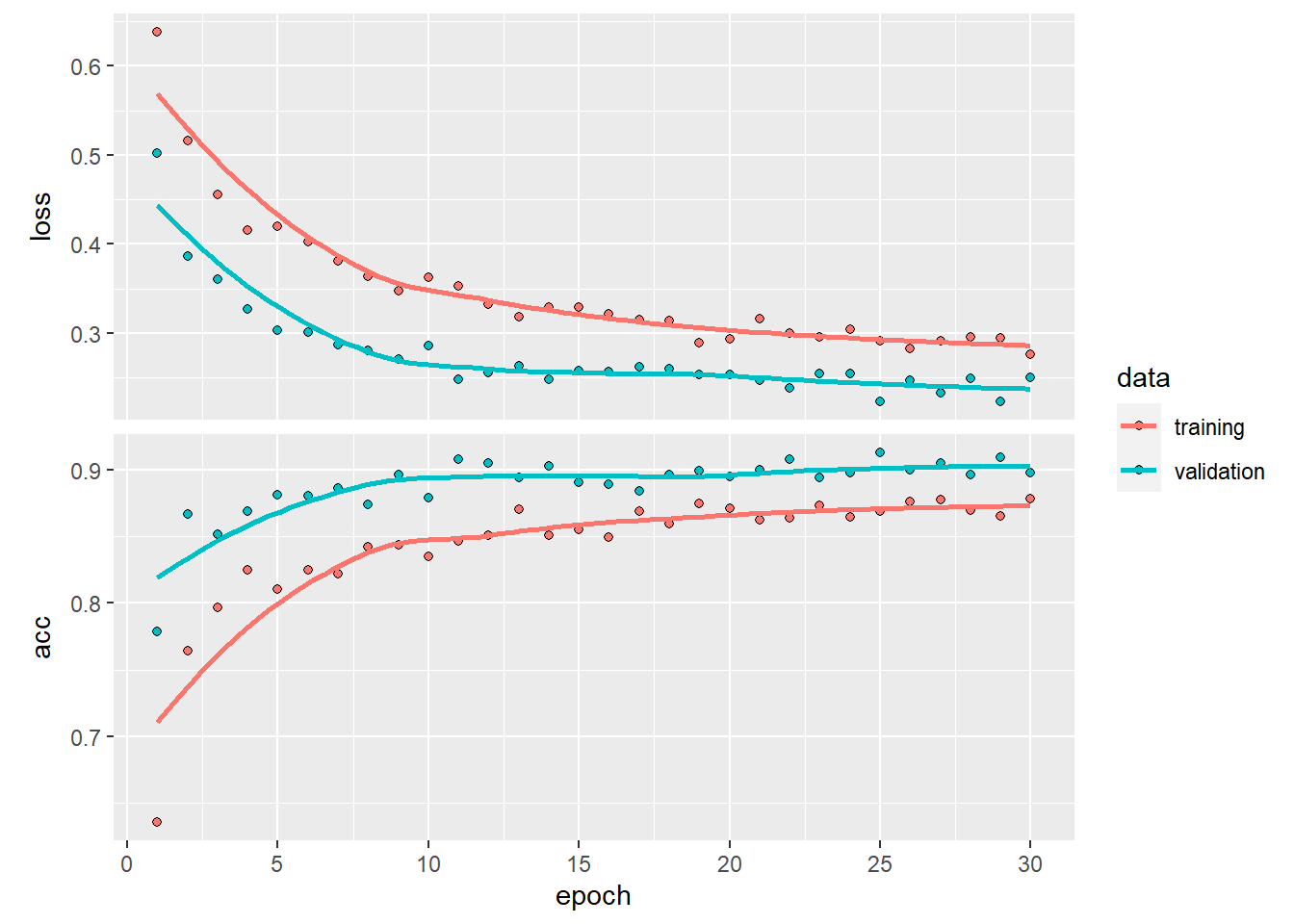
さっきとは異なり、評価セットの正確度が90%近くに上がっています!少ないデータでも訓練済みCNNを用いて十分な学習が行えたと考えられます。
でもGPUを使っても結構時間がかかります…。
テストデータを使って、正答率を見てみます。
model %>% evaluate(test_generator, steps = 50)## loss acc
## 0.2677287 0.890000090%近く正解してます!これは上出来ですね。
さらに精度を高めるためファインチューニング
このモデルでもいい感じですが更なる正答率を求めてファインチューニングしました。モデルの伝播を止めていた深い層の部分を凍結解除して再度学習させます。
model %>% compile(
loss = "binary_crossentropy",
optimizer = optimizer_rmsprop(learning_rate = 1e-5),
metrics = c("acc")
)
history <- model %>% fit(
train_generator,
steps_per_epoch = 100,
epochs = 100,
validation_data = validation_generator,
validation_steps = 50
)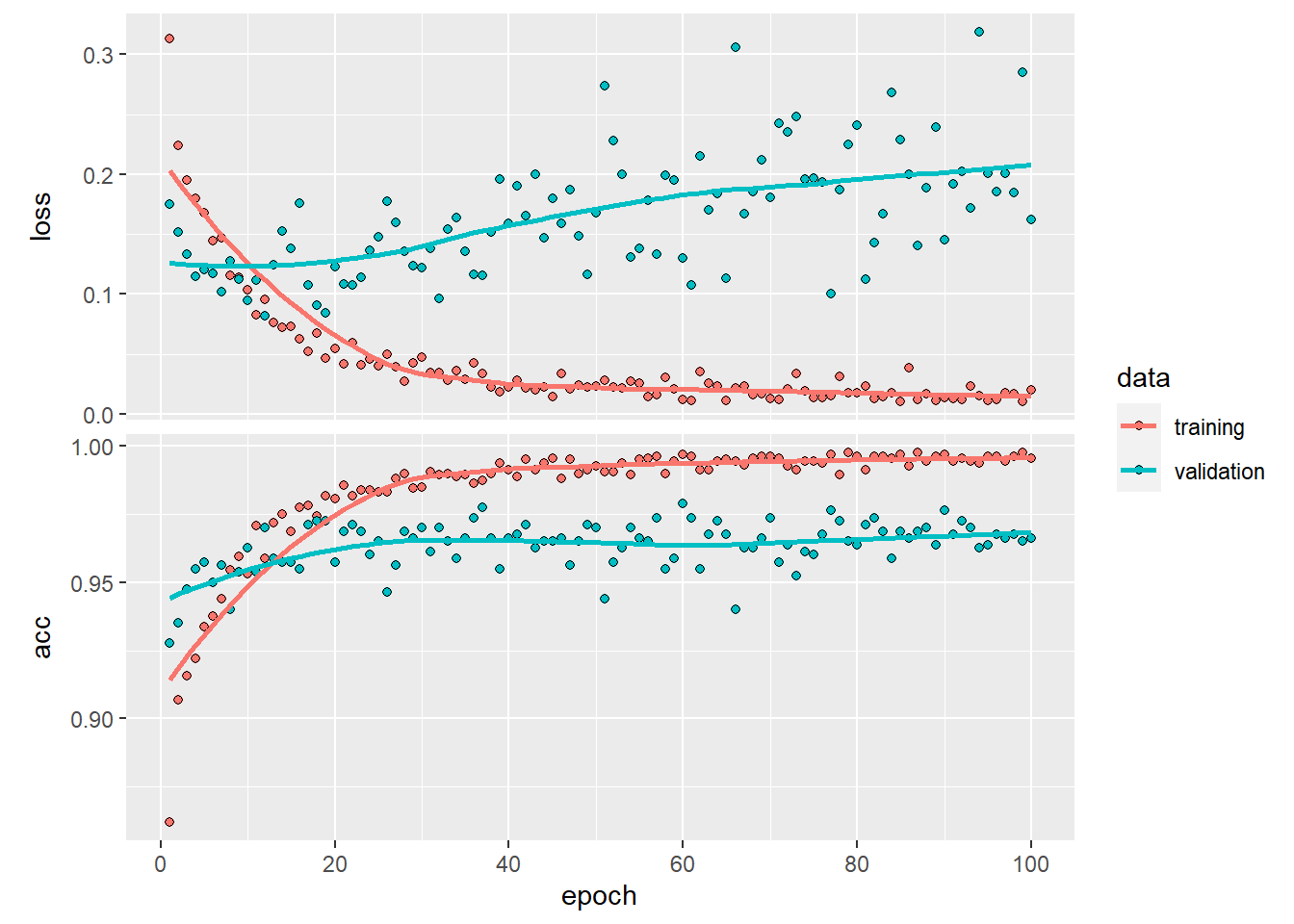
正確度は前回より6ポイントアップして96%ほどでした。テストデータを入れてみます。
model %>% evaluate(test_generator, steps = 50)## loss acc
## 0.3284974 0.9637500なんと96%とかなり高い正答率を出しています。犬と猫を判別できているといってよさそうです。 頑張って作ったモデルなのでとりあえず保存します。
# モデルの保存
model %>% save_model_hdf5("cats_dogs_fine.h5")保存も簡単で便利です。後から学習したモデルを利用したり、共有したりできます。
作ったモデルに愛犬を判別させる!!
いよいよ来ましたね。では、保存したモデルを使ってチェリーちゃんを判別させてみます(下の画像がチェリーです)。

犬だけだと本当に識別できてるかわからないので、昔に保護した子猫の画像との判別をさせてみます(下の画像が名もなき保護猫)。

犬と猫を判別できるかやってみます。
model %>% evaluate(cherry_generator, steps = 1)## loss acc
## 2.174317e-07 1.000000e+00正答率が1.00なので2枚の犬と猫を無事判別することができました。自分で作ったモデルがしっかり機能しているのはうれしいものがありますね。
さらに、チェリー25枚、保護猫25枚で判別させてみましたが結果は80%止まりでした。顔の向きが正面でなかったり、対象が近すぎるor遠すぎる、別の物体(人や花)が画像に含まれていったなどで判別が難しい画像が含まれていたことが原因だと考えられます。対象の位置も考慮したモデルや学習をしたら改善されそうです。
最後に
今回は、犬猫判別AIを作って愛犬を判別してみました。
GPUを使うと学習が早く進むのでストレスフリーでした。さすがに今回の後半に組んだモデルは重かったので時間はかかりましたが、CPUではそもそも負荷が大きすぎて心配になるレベルな計算だったので、GPUのありがたみを感じました。
tensorflowとkerasも便利なうえに、R上ですべて完結できるのでよかったらやってみてください。